Another Christmas is coming in few days. It's time to look back at 2016 and see what IEEE Working Group on Energy Forecasting has done:
Next year will be even more exciting:
Happy Holidays and Happy Forecasting!
- The LinkedIn group for IEEE WGEF has grown to 1642 members as of today, up from 1507 same time last year. LinkedIn has split the Global Energy Forecasting Competition group from WGEF. The GEFCom group now has 657 members, up from 485 same time last year.
- IEEE Transactions on Smart Grid published the special section we edited on Big Data Analytics for Grid Modernization.
- International Journal of Forecasting published the special section Pierre Pinson and I edited on Probabilistic Energy Forecasting.
- Hamidreza Zareipour, Pierre Pinson and I taught the IEEE tutorial Energy Forecasting in the Smart Grid Era at PESGM 2016 in Boston for the fourth and last time.
- Ning Zhang and Pierre Pinson prganized and chaired a panel session "Offering, Pricing and Managing Uncertainty and Variability in Power System Operations with Significant Renewable Energy Integration". The session room was over-crowded by 100+ people.
- We kicked off the qualifying match of the Global Energy Forecasting Competition 2017, with 140+ teams from 30 countries.
Next year will be even more exciting:
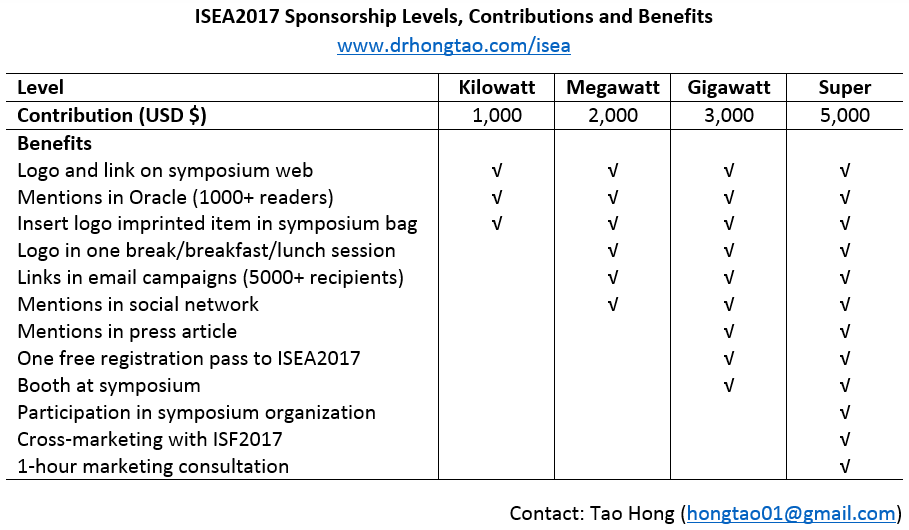
- We will hold the International Symposium on Energy Analytics (ISEA2017), the first-ever gathering of world-wide energy forecasters in Cairns, Australia, the only place on earth with two World Heritage sites side-by-side, Great Barrier Reef and the Daintree Rainforest.
- We will conclude GEFCom2017 at ISEA2017 with the winner presentations and prizes.
- A PESGM2017 panel session on multiple energy systems is being organized by Ning Zhang and myself.
- I will be editing a special issue for the Power & Energy Magazine on big data analytics. The papers are by invitation only. If you have any good idea and would like to present it to thousands of PES members through this special issue, please let me know.
- We didn't have the bandwidth for JREF this year. We will try to conduct the JREF survey next year.
Happy Holidays and Happy Forecasting!